







2018/11/07
2192
人工智能靠什么更快更强?答案是好奇心
文章的开头,先抛出一个问题:大家在玩电子游戏的时候,一门心思投入进去,会发现自己根本停不下来,是什么原因导致的呢?
这个问题可能有些宽泛,无法给出一个确切的答案。但如果你想要把接新任务,升级或者再玩一把等一系列概括起来,最简单的解释就是“好奇心”——只是想看看接下来会发生什么。事实证明,在指导人工智能玩电子游戏时,好奇心是一个非常有效的动力。
非营利人工智能研究公司OpenAI本周发布的一项研究解释了一个具有好奇心的AI agent如何攻克经典的1984 Atari游戏Montezuma‘s Revenge。熟练掌握Montezuma’s Revenge算是人工智能的一大进步,但不能将其等同于打败Go或Dota 2的里程碑。谷歌旗下的人工智能公司DeepMind2015年发布了一篇开创性论文,解释AI如果通过深度学习在许多Atari游戏里获得高分,击败强大的人类玩家,其中Montezuma’s Revenge是唯一一款得分为0的游戏,算法未能学习如何去玩这个游戏。
游戏难度高的原因在于它的操作方式与AI agent学习的方式不匹配,这也揭示出机器学习存在盲点。
要想AI agent掌握电子游戏的玩法,通常需借助强化学习的训练方法。在这种训练中,agent会被放入虚拟世界,并且会因为某些结果而获得奖励(如增加分数),或是受到惩罚(如失去一条命)。AI Agent开始随机玩游戏,且能学会在反复试验之后改进其策略。强化学习通常被看作是构建智能机器人的关键方法。
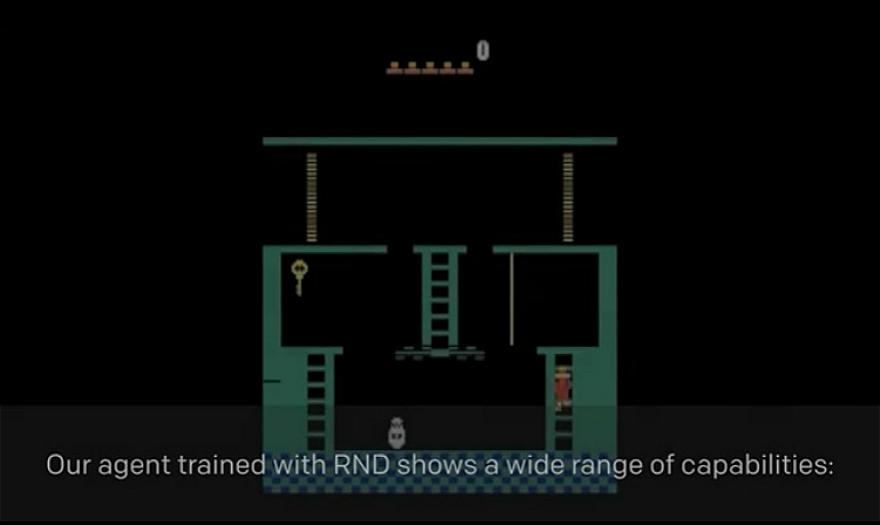
Montezuma‘s Revenge的问题在于它不能为AI agent提供定期奖励。这是一个益智类游戏,玩家必须探索地下金字塔,躲避陷阱和敌人,同时收集解锁门和特殊物品的钥匙。如果你正在训练AI agent攻克这款游戏,可以在它活着通过各个房间并收集钥匙时给予其一定的奖励。但是你该如何教他保存其他物品的钥匙,并使用这些物品来克服陷阱并完成关卡呢?
答案就是:好奇心。
在OpenAI的研究中,他们的agent获得奖励不仅仅是因为跳过尖峰,还为了探索金字塔的新板块。探索新板块的好奇心是一大动力,也促成了agent在游戏中优于人类的表现,机器人在9次闯关中平均得分10000(人类平均得分4000)。OpenAI称,在一次运行中,agent甚至通过了第一关。
OpenAI的Harrison Edwards告诉The Verge:“我们目前已经开发出一个可以探索大量房间,获得大量奖励,偶尔还能闯过第一关的系统。”并补充道,游戏的其他关卡跟第一关类似,游戏通关“只是时间问题。”
攻克“NOISY TV PROBLEM”
OpenAI并非第一家尝试这种方法的实验室,AI研究人员几十年来一直在利用“好奇心”的概念作为诱因。他们之前也曾将此应用于Montezuma’s Revenge,但如果没有指导人工智能从人类的例子中学习,就不会如此成功。
然而,尽管这里的一般理论已经确立,但构建特定解决方案仍然具有挑战性。例如,基于预测的好奇心仅在学习某些类型的游戏时有用。它适用于马里奥这类游戏,游戏过程中探索空间大,关卡设置多,且充斥着从未见过的怪物。但对于Pong这种简单游戏,AI agent更愿意打持久战,而不是真正击败他们的对手。(或许是因为赢得比赛比游戏中球的路径更好预测。)


深耕自动化,成就多元产业应用
欢迎莅临广州国际智能制造技术与装备展览会!
主办单位官方微信

